Part 5: Data & Lexicon Construction (CSI-HDC)
The foundation of the GDS system is the Semantic Base, a large-scale lexicon of “semantic particles” generated by the CSI-HDC (Conceptual State Injector using Hyperdimensional Computing) pipeline. This pipeline processes and synthesizes information from multiple data sources to generate concept representations with physics-inspired properties.
Primary Data Sources
| ConceptNet |
data/raw/assertions.csv |
Provides the primary structural graph of common-sense relationships (e.g., UsedFor, CapableOf, PartOf). It forms the backbone of explicit knowledge. |
| Numberbatch |
data/raw/numberbatch.txt |
Pre-trained 300-dimensional word embeddings. Primary source for generating 20,000-bit binary HDC vectors via the Julia HDC server, and fallback for affective score calculation. |
| NRC-VAD Lexicon |
data/raw/nrc_vad/ |
Provides affective scores for English words across three dimensions: Valence (pleasure/displeasure), Arousal (intensity), and Dominance (control). This is the source for the spin property of English particles. |
| German Norms |
data/raw/german_norms/ |
The German equivalent of the NRC-VAD lexicon, providing affective scores for German words. |
| OEWM Lexicons |
data/oewm_lexicons/ |
Open English, German, and Romanian WordNet data. This is a crucial source for normalization, synonymy (aliases), and word frequency priors. It significantly boosts the quality of mass calculation and the coverage of other lookups. |
| BabelNet Cache |
data/enrichment/babelnet_cache.db |
Local SQLite database caching BabelNet API results. Used in enrichment iterations to add high-quality multilingual relations, expanding the semantic graph over time. |
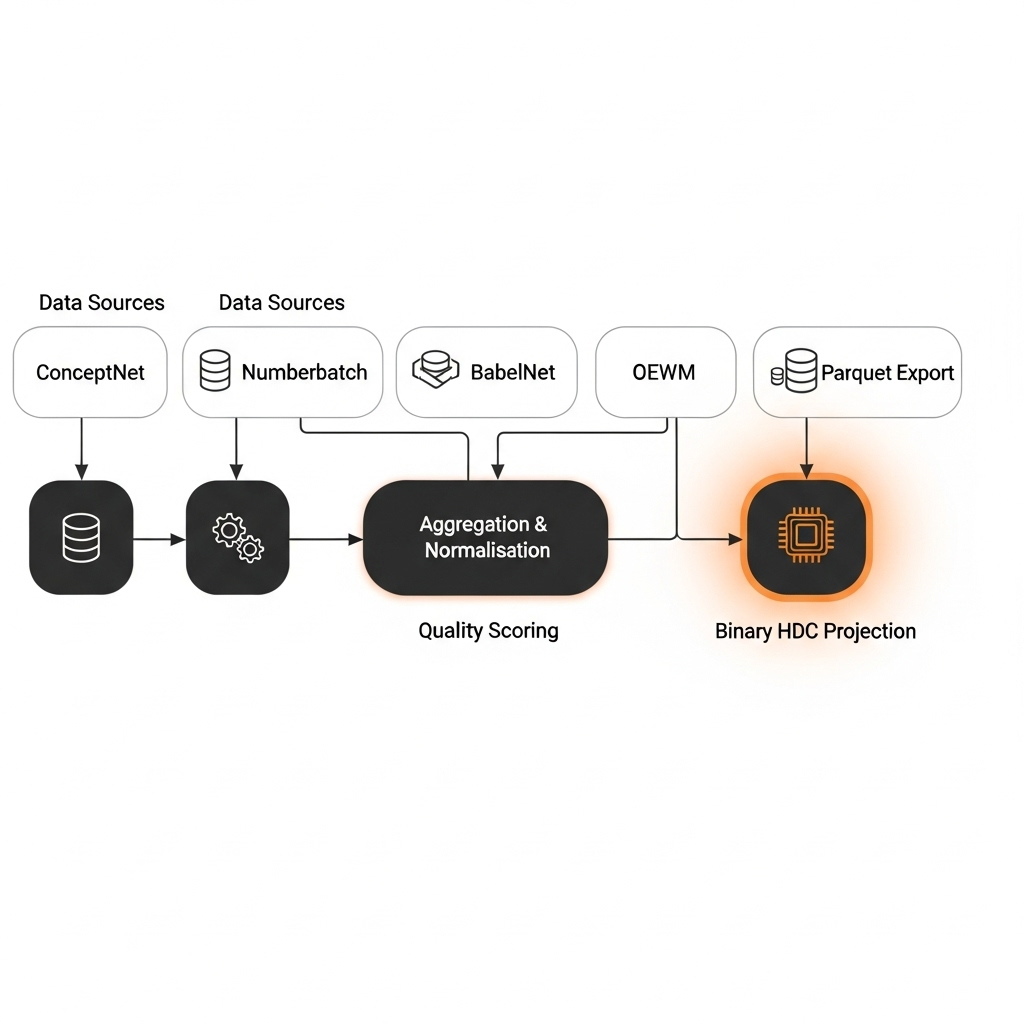
The Generation Pipeline (LexiconBuilder)
The process is orchestrated by the LexiconBuilder in the Rust codebase and follows several key stages:
- Aggregation: Raw assertions from ConceptNet are streamed and aggregated into a per-concept map, building a preliminary list of relations.
- Normalization & Enrichment: Lemmas are normalized using OEWM. This step also discovers aliases (synonyms) that will be used in later stages.
- Quality Scoring: Each potential concept is scored based on a set of heuristics: its connectivity in the graph, whether it has a Numberbatch embedding, and its coverage in affective lexicons.
- Filtering: Concepts that do not meet a minimum quality threshold (e.g.,
min_relations) are discarded.
- Property Calculation: For each high-quality concept:
- Mass (
m0) is calculated from graph connectivity, boosted by frequency priors from OEWM.
- Spin (
s) is derived from affective lexicons (NRC-VAD, German Norms).
- Charge (
q) is generated by the Julia HDC server, which expands 300D Numberbatch embeddings into 20,000-bit binary hypervectors—this is the CSI-HDC tokenization step that replaces traditional token embeddings.
- Export: The final collection of
SemanticParticle objects is written to a compressed Parquet file (ZSTD compression), forming the Semantic Base for the GDS runtime.